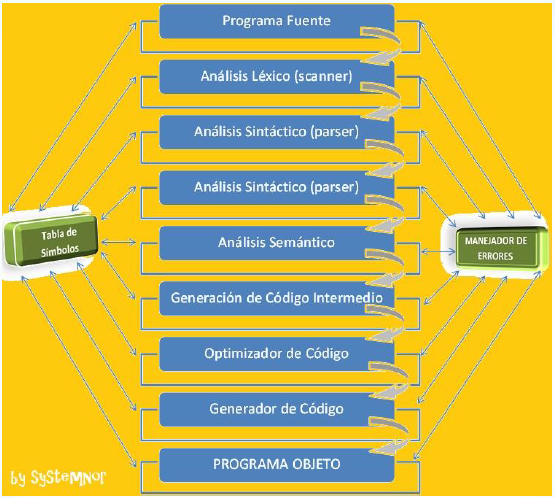
Tabla de Símbolos.
Almacena todos los nombres declarados en el programa y sus atributos (tipo, valor, dirección, parámetros, etc).
Se usa en las distintas fases del compilador.
Estructura de datos.
Almacena información sobre:
- Los identificadores.
- Las palabras reservadas.
- Las constantes.
Contiene una entrada para cada uno de los símbolos definidos en el programa fuente.
Sobre los identificadores, y opcionalmente sobre las palabras reservadas y las constantes.
Información sobre el lexema, tipo de datos, ámbito y dirección en memoria.
Por cada entrada en la tabla de símbolos habrá que guardar:
- Lexema correspondiente.
- Tipo.(depende de la implementación).
- Ámbito.(depende de la implementación).
- Dirección de memoria asignada.
- Forma.(depende de la implementación).
¿Utilidad de la tabla de símbolos?
- Analizador Léxico: Pasa en el token y la entrada de la TS creada.
- Analizador Sintáctico y Semántico: busca el token y si no la encuentra crea una nueva entrada.
Datos que se almacenan:
Para un array:
- Tipo de los elementos.
- Número de elementos.
- Limites inferior y superior.
Para una función:
- Número de parámetros.
- Tipo de los parámetros.
- Forma de paso de parámetros.
- Tipo de retorno.
Operaciones Principales.
- Insertar: introduce un símbolo tras una declaración.
- Buscar: recupera información asociada a un símbolo.
- Eliminar: borra la información.
Ejemplo de Uso I.
Declaración previa al uso de variables:
- En las declaraciones, inserción en la TS.
Aparición de una variable en una sentencia, búsqueda en la TS:
- Si se encuentra Fue declarada.
- Si no se encuentra Error de compilación.
Ejemplos de Uso II.
Acceso a una posición de un array:
- Declaración > Inserción en la TS.
- Acceso a un array > Búsqueda en la TS.
- Comprobación de tipo array.
- Comprobación acceso a una posición válida.
Tabla de Símbolos.
Ejemplo:
- Analizador Lexicográfico: Inserta en TS cada id que detecta y si corresponde da error si ya existe.
- Analizador Sintáctico: Inserta el tipo de id.
- Analizador Semántico: Verifica que cada id sea declarado antes de usarlo y recupera el tipo de id.
- Generación de Código Intermedio: recupera tipo y dirección del id.
- Generación de Código: Inserta y recupera información sobre la memoria asignada.
Estructuras usadas para implementar una tabla de símbolos.
Lista
- Simple de implementar.
- Lenta cuando se trabaja con muchos identificadores.
Árbol
- Rápida.
- Consume más memoria.
- Es útil cuando hay muchas declaraciones.
Tabla de Hashing
- Rápida.
- Difícil de implementar.
- Se debe definir una función de hashing apropiada para evitar colisiones.
Operaciones sobre TS.
- Búsqueda (lexema): entero;
- Inserción (lexema, descriptor): boolean;
- Obt_atributo (lexema, atributo): valor;
- Eliminación (lexema): entero.
Manejo de palabra

Si el scanner diferencia entre un identificador y una palabra reservada, entonces devuelve al parser el código correspondiente. Aquí no se requiere el ingreso de la palabra clave en la TS.
Si el scanner no las diferencia de los identificadores:
- Pueden almacenarse en una tabla separada.
- Estar inicializadas al principio de la TS.
- Una entrada, en TS para una palabra reservada.
Entrada en la TS.
Una primera desagregación de una entrada de la tabla de símbolos.
No todos los atributos se introducen a la vez, estos se completan conforme avanzan las etapas de compilación.
Parte Fija.
Parte Variante.
- Depende del objeto computacional asociado con el identificador.
- Variable Simple: la parte variante es vacía excepto cuando se admitan valores de inicialización.
- Variable Estructurada (Arreglo).
Procedimiento o Función.
Operaciones sobre TS: Lenguajes estructurados a bloques.
Crean un ámbito, una visibilidad y un tiempo de vida para los identificadores.
Tareas que se deben realizar cuando se ingresa a un nuevo bloque:
- Dar de alta un nuevo bloque.
- Insertar cada identificador encontrado en dicho bloque.
Tareas realizadas cuando se finaliza el análisis de un bloque:
- Eliminar cada identificador en el bloque.
- Eliminar el bloque.
Operaciones sobre TS: Lenguajes Estructurados a Bloques.
Cuando se busque un identificador en la TS se debe retornar el último identificador insertado, es decir, el identificador declarado en el bloque actual, si en tal bloque no existe el identificador buscarlo en el bloque que lo contenga, y así sigue hasta encontrarlo. Si el identificador no se encuentra en ninguno de los bloques anidados entonces no existe.
Ejemplo: